
Closing the Inference Gap: Why Your Brand Is Invisible to LLMs (And What to Do About It)
GEO, AEO, LLM brand monitoring, and AI visibility tools for developers who want Share of Voice in zero-click results

If your brand doesn't appear in a zero-click result from GPT-4o, Claude, or Gemini, you don't exist to that user. That query never hits your analytics. It doesn't generate a backlink. It resolves entirely inside the model's context window — and you get nothing.
That's the inference gap: the delta between what users ask LLMs and what your brand actually appears in. Traditional SEO measures impressions and clicks. GEO (Generative Engine Optimization) and AEO (Answer Engine Optimization) measure something harder — whether LLMs synthesize your brand into their outputs at all, and whether those answers are accurate or riddled with hallucination rate artifacts from stale training data.
What Is Inference Traffic and Why Your Funnel Is Missing It
Inference traffic is the volume of user queries resolved by LLM inference rather than a traditional search engine. With models running Test-Time Compute scaling and System 2 Thinking via Chain-of-Thought (CoT) and Thinking Mode, LLMs now handle nuanced research queries that previously required five browser tabs. Perplexity, ChatGPT, and similar tools collapse that research into a single grounded response — and your brand either appears in it or it doesn't.
This isn't theoretical. Users are increasingly trusting LLM-synthesized answers over raw search results. They skip the SERP entirely. Your SEO ranking becomes irrelevant if you don't show up in the model's retrieval layer. The entire concept of Share of Voice (SOV) needs to be re-measured for AI-native search.
How LLM Brand Monitoring Actually Works
")
LLM brand monitoring means systematically querying multiple models — GPT-4o, Claude, Gemini, Llama, Mistral — with your target prompts and measuring: Does your brand appear? In what context? With what accuracy? How does it compare to competitors?
The challenge is that each model has a different knowledge graph representation of your brand, depending on its training data, Fine-Tuning history, RLHF alignment, and whether your content made it into Synthetic Data pipelines. A model trained with LoRA/QLoRA adapters on narrow domain data may represent your brand differently than a base model with high Parameter Count. Quantization and Knowledge Distillation can further compress or distort brand associations.
Monitoring requires structured probing across model families, tracking Grounding quality (does the model cite real facts about you?), and flagging Prompt Injection-style contamination where competitor content hijacks your brand mentions.
LLM Competition Research and Share of Voice Benchmarking
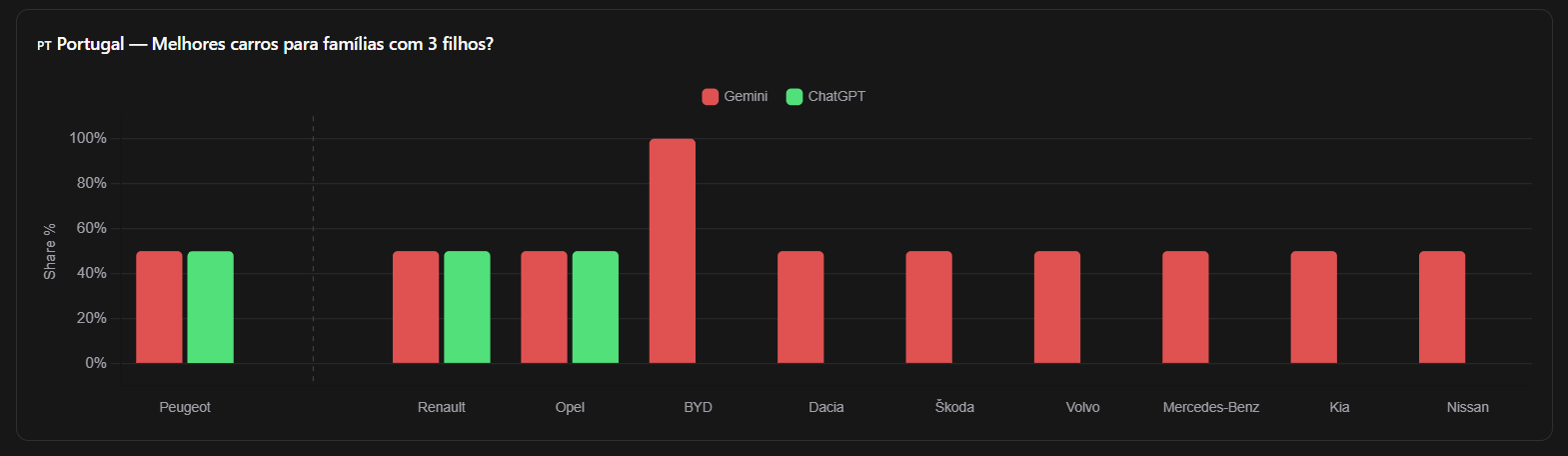
LLM Competition Research goes beyond keyword rankings. You're mapping which brands dominate AI-synthesized answers in your category, what Few-Shot Prompting patterns favor competitors, and which RAG-augmented responses systematically exclude your content.
RAG (Retrieval-Augmented Generation) pipelines are increasingly the backbone of enterprise AI products. If your content isn't indexed in the retrieval layer, your brand is invisible regardless of how well-optimized your website is. Token efficiency matters too — content that wastes tokens on filler gets deprioritized when models trim context for Latency optimization.
AI Visibility benchmarking means running consistent prompt batteries across models — with Multimodality considerations where image or document context changes retrieval — and tracking your SOV week over week. This is the new competitive intelligence layer.
Building Your GEO Stack with LLM Search Console
: The Evolution of Your SEO Strategy | The Show and Tell Agency")
LLM Search Console is built for exactly this workflow. It handles Agentic Workflow orchestration across model APIs using MCP (Model Context Protocol) and Function Calling to run structured prompt batteries at scale. Multi-Agent Orchestration lets you parallelize brand monitoring queries across GPT-4o, Claude, and Gemini simultaneously — with normalized scoring so you're comparing apples to apples.
The platform tracks your AI Visibility score over time, surfaces Constitutional AI alignment issues (models that refuse to mention your brand due to policy triggers), and flags when competitor content is outranking you in RAG retrieval layers. It accounts for MoE (Mixture of Experts) model routing — where different expert layers may have different brand representations — and gives you a unified dashboard. World Models that encode causal reasoning about your market may represent your brand differently across question types, and the platform tracks that variance.
Dev Log: Quick Wins
Run a zero-click audit today. Query 3 LLMs with your top 5 "what is the best [your category]" prompts. Record whether your brand appears. This is your baseline inference gap.
Check RAG eligibility. Verify your key pages are crawlable, have clean structured data, and use concise factual language. Token efficiency = better RAG recall.
Monitor hallucination rate. Ask LLMs to describe your product. Log inaccuracies. These are training data artifacts — fixing them requires publishing accurate, authoritative content at scale.
Track SOV weekly. Use LLM Search Console to automate competitive SOV tracking across model families. Set alerts when your AI Visibility score drops.
Optimize for Grounding. Write content that is factual, structured, and citable. Models with Grounding enabled (Gemini, Perplexity) prefer content that resolves cleanly to verifiable claims.
The inference gap is real, measurable, and growing. The brands that close it now will own the AI-native search layer. Start at llmsearchconsole.com.