
Traditional SEO Is Down 40%. Here's What's Eating Your Traffic.
Inference Traffic is the new organic search. If you're not measuring it, you're flying blind.

If your organic traffic chart looks like a ski slope right now, congratulations — you're not being penalized by an algorithm update. You're being eaten alive by inference traffic. And your current stack has zero visibility into it.
The Problem: You’re Optimizing for a Search Engine That’s Losing Users

Here’s a stat that should make every SEO team stop mid-sprint: traditional search traffic is down an average of 40%. Not because your content got worse. Not because your backlinks rotted. But because a growing slice of your target audience is now getting answers directly from ChatGPT, Gemini, Grok, Claude, and Perplexity — without ever touching a SERP.
This is Inference Traffic — the queries your site should be answering, now being intercepted and responded to by a large language model. And here’s the brutal irony: if an LLM is trained on your content, cites your domain, or retrieves your pages via RAG (Retrieval-Augmented Generation), you might be generating value for users you’ll never see in Google Analytics. Think of your current SEO strategy like an optimized SQL query hitting a database that’s been deprecated. Perfectly tuned. Completely wrong table.
Old SEO vs. LLM SEO: A Brutal Comparison

The inference gap is the new page 2. If a model doesn’t include your brand in its generated response — you don’t exist. Not for that user. Not for that query. Here’s how the full stack has shifted:
Target
Old SEO: Crawlers & PageRank | LLM SEO: Context windows & token budgets
Success Signal
Old SEO: Keyword ranking | LLM SEO: Brand mention in AI responses
Key Technique
Old SEO: Backlink building | LLM SEO: Structured data + knowledge graph density
Traffic Source
Old SEO: Google/Bing SERPs | LLM SEO: Inference engines (ChatGPT, Perplexity, Grok, Gemini)
Failure Mode
Old SEO: Page 2 | LLM SEO: Inference gap — the model doesn’t know you exist
What Agentic Workflows Mean for Your Visibility

Here’s where it gets weirder. As LLM-based agentic workflows proliferate — AI agents browsing the web, comparing products, booking services — they’re not just answering questions. They’re making decisions. An agent shopping for a B2B SaaS tool doesn’t click 10 blue links. It queries an LLM, gets a shortlist, and executes.
If you’re not on that shortlist, you’re not in the funnel. This is why GEO (Generative Engine Optimization) is no longer a niche term — it’s the operational layer your content, dev, and marketing teams need to treat like P0.
The Source of Truth: LLM Search Console
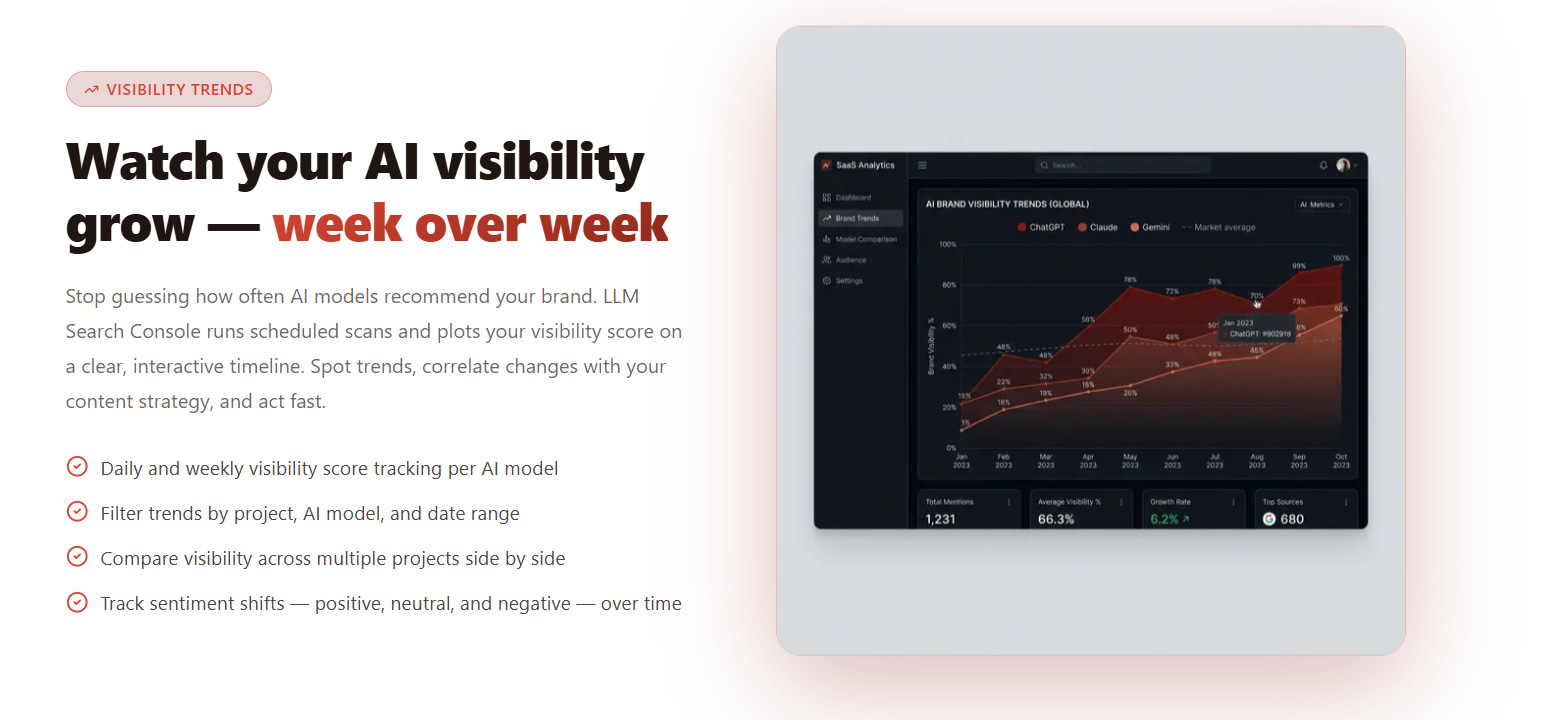
The only way to know whether you’re winning or losing the inference war is data. That means systematically querying the major LLMs, tracking when and how your brand appears, and monitoring citation rates across context windows.
LLM Search Console tracks your brand’s mentions across ChatGPT, Gemini, Grok, Claude, and Perplexity — giving you the inference equivalent of a keyword ranking report. Think of it as console.log() for your AI visibility: you can’t debug what you can’t see. Benchmark your token efficiency (how concisely your content fits into a model’s context window), identify inference gaps (queries where competitors appear but you don’t), and measure visibility trends over time. Visit llmsearchconsole.com to run your first report.
Quick Wins: Dev Log for Your First 30 Minutes

Create or optimize your llms.txt file — Place it at yourdomain.com/llms.txt and list key pages, FAQs, and structured context you want AI crawlers to prioritize. It’s the robots.txt equivalent for the inference layer.
Audit your structured data — Tighten your schema markup (@type: Organization, Product, FAQPage). LLMs and RAG pipelines weight structured data heavily when deciding what to surface.
Run your first inference report on LLM Search Console — See which queries mention your brand and which are inference gaps you need to close. This is your new baseline metric.
Rewrite your About page for token efficiency — Strip jargon, compress claims, make every sentence independently quotable. LLMs cherry-pick; make yours worth cherry-picking.
Strengthen your knowledge graph density — Get mentioned on authoritative third-party sources: Wikipedia, Wikidata, Crunchbase, industry publications. The more nodes pointing to you, the more likely you are to be retrieved in a RAG pipeline.
The game has changed. The players who ship fast on GEO now will own the inference layer the same way early adopters owned page 1 in 2012. Don’t be the developer who’s still writing jQuery in a React world.
Start measuring. Start optimizing. The inference gap won’t close itself.